

Ist RAG der Schlüssel zu KI-gestütztem Content Delivery?
Künstliche Intelligenz (KI) steht aktuell im Mittelpunkt öffentlichen und wissenschaftlichen Interesses. Auch in der Technischen Kommunikation wird intensiv untersucht, wie KI beim Erstellen, Verwalten und Bereitstellen technischer Inhalte unterstützen kann. Besonders viel Aufmerksamkeit erhält dabei der Ansatz der Retrieval-Augmented Generation (RAG).
Was genau ist RAG?
Der Begriff Künstliche Intelligenz umfasst ein breites Spektrum an Technologien. In der Technischen Kommunikation liegt der Fokus dabei zumeist auf sogenannten Large Language Models (LLMs). Diese Modelle werden auf großen Mengen an Textdaten trainiert und generieren Texte auf Basis statistischer Wahrscheinlichkeiten.
Trotz ihrer Leistungsfähigkeit sind LLMs in einigen Punkten limitiert:
- Sie kennen keine internen, domänenspezifischen Inhalte, sofern diese nicht Teil der Trainingsdaten waren.
- Ihr Wissen hat einen festen Stand: den sogenannten Knowledge Cutoff Date. Informationen nach diesem Zeitpunkt sind nicht enthalten.
Um aktuelle oder domänenspezifische Informationen in ein LLM zu bringen, müsste das Modell regelmäßig neu trainiert werden. Das ist jedoch aufwändig und kostenintensiv. Eine deutlich flexiblere Alternative bietet Retrieval-augmented Generation (RAG). Dabei werden die benötigten Informationen nicht im Modell selbst gespeichert, sondern bei einer Anfrage im Kontext mitgegeben. Mithilfe einer semantischen Suche (siehe auch Blogpost zu Ontologien) werden zunächst passende Inhalte ermittelt. Diese Treffer werden gemeinsam mit der ursprünglichen Nutzeranfrage an das LLM übergeben, das daraufhin eine kontextbezogene Antwort generiert.
Wieso reicht einfaches RAG nicht aus?
Grundsätzlich funktioniert der RAG-Mechanismus recht zuverlässig, wenn es darum geht, Fragen zu allgemeinen Themen zu beantworten. Im Rahmen einer Bachelorthesis wurde das am Beispiel des PI-Fans getestet. Dabei zeigte sich, dass der RAG-Chatbot die meisten Fragen zu diesem Datensatz sinnvoll beantworten kann.
Allerdings gelingt das nicht bei allen Anfragen gleichermaßen. Besonders dann, wenn eine Frage implizites Wissen voraussetzt oder sich auf verschiedene Produktvarianten beziehen kann, stößt das System an seine Grenzen. Solche Inhalte müssen zunächst erkannt und gegebenenfalls aufgeschlüsselt werden, bevor eine korrekte Antwort möglich ist.
Die Technische Dokumentation stellt darüber hinaus besondere Anforderungen an die Qualität der bereitgestellten Informationen. Aufgrund rechtlicher und sicherheitstechnischer Vorgaben ist es entscheidend, dass ein System zur Auslieferung technischer Informationen ausschließlich korrekte und relevante Antworten liefert.
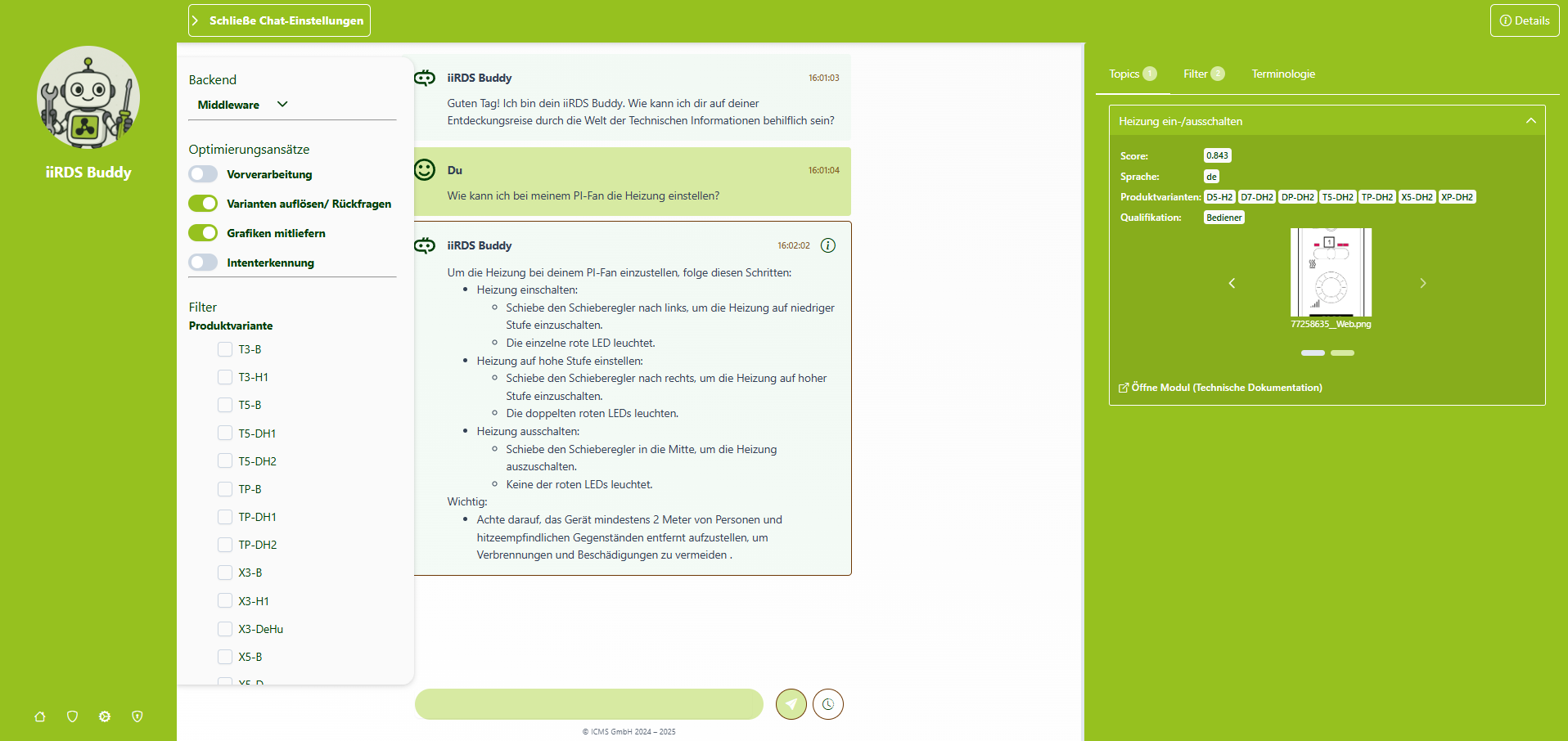
ICMS-eigenes Benutzerinterface
Um das Potenzial solcher Systeme besser bewerten zu können, hat die ICMS zu Analyse- und Testzwecken ein eigenes Benutzerinterface entwickelt. Damit lassen sich neben den generierten Antworten auch die zugrunde liegenden Module und Metadaten der semantischen Suche nachvollziehen. Hiermit kann besser nachvollzogen werden, welche Inhalte gefunden werden und wieso. In einer Bachelorarbeit wurden prototypische Verbesserungsansätze in das System eingearbeitet und die Ergebnisse durch das Benutzerinterface analysiert. Dabei lag der Fokus auf den folgenden Bereichen:
- Terminologie: Nutzer verwenden mitunter Produktbezeichnungen oder Formulierungen, die im Datensatz nicht vorkommen. Das erschwert die semantische Suche erheblich, da relevante Inhalte möglicherweise nicht erkannt oder falsch zugeordnet werden.
- Absicht der Anfrage: Ein Dokumentations-Chatbot sollte nicht auf jede Anfrage mit der gleichen Antwortstrategie reagieren. Oft ist unklar, ob eine Frage auf allgemeine Informationen oder auf konkrete Handlungsanweisungen abzielt. Ohne eine zuverlässige Erkennung der Nutzerintention besteht die Gefahr, am eigentlichen Bedarf vorbeizuantworten.
- Medieneinbindung: LLMs arbeiten rein textbasiert. Visuelle Inhalte wie Bilder oder Diagramme, die in den zugrunde liegenden Dokumenten enthalten sind, gehen in der Antwortgenerierung verloren. Das kann problematisch sein, wenn sich die Information im Text direkt auf solche visuellen Elemente bezieht.
- Variantenauflösung: Viele Produkte existieren in unterschiedlichen Ausführungen mit teils erheblichen Unterschieden. In Nutzeranfragen wird jedoch oft nicht klar benannt, auf welche Variante sich die Frage bezieht. Ohne eine geeignete Strategie zur Erkennung der gemeinten Produktvariante besteht das Risiko, unpassende oder fehlerhafte Antworten zu liefern.

Von simplem RAG zu agentischer KI
Die oben genannten Herausforderungen zeigen: Eine einfache Pipeline nach dem Muster Frage → Retrieval → Ausgabe reicht oft nicht aus.
Stattdessen braucht es weiterführende Schritte, die die Intention der Anfrage analysieren, den passenden Content auswählen und die Antwortform optimieren. Hier kommen sogenannte agentische Systeme ins Spiel. Diese sind Systeme, in denen ein LLM durch Tools und Datenquellen erweitert wird und werden in zwei Varianten aufgeteilt:
- KI-Agenten sind Systeme, in denen ein LLM selbst entscheidet, welche Tools oder Datenquellen es zur Lösung einer Anfrage heranzieht. Das Modell ruft sich selbst mehrfach auf und bewertet die Antwortqualität iterativ.
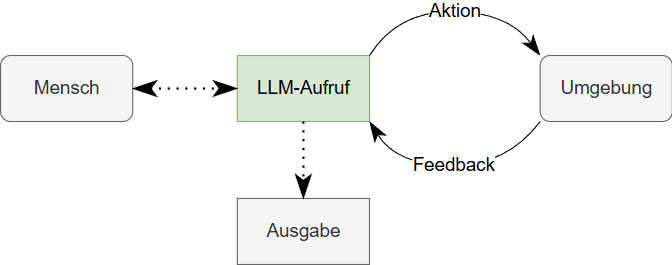
- Agentische Workflows hingegen bestehen aus klar definierten, aufeinanderfolgenden Schritten: z. B. Intentionserkennung, Produkterkennung, semantisches Retrieval, Textgenerierung, Antwortvalidierung. Jeder Schritt kann ein Tool, eine Datenabfrage oder ein LLM-Call sein.

Gerade für die Technische Kommunikation ist ein strukturierter Workflow meist vorzuziehen. Er ist transparenter, kontrollierbarer und besser nachvollziehbar als ein frei agierender KI-Agent. Allerdings erfordert er auch ein tiefes Verständnis der eigenen Inhalte, Anwendungsfälle und Zielgruppen.
Bedenken beim Einsatz von KI in der Technischen Kommunikation
Beim Einsatz von KI zum Ausliefern von Inhalten müssen aber noch generelle Fragen geklärt werden:
- Für welche Inhalte ist es okay, sie durch LLMs zusammenfassen zu lassen?
- Wie strukturiert und ausgezeichnet sind die zugrundeliegenden Daten?
- Wie kann sichergestellt werden, dass nur korrekte und kontextuell passende Antworten genereiert werden?
Fazit
Wer plant, einen KI-gestützten Chatbot für technische Inhalte aufzubauen, sollte den RAG-Ansatz nicht als alleinige Lösung betrachten. Zwar bietet er großes Potenzial für die intelligente Content-Auslieferung, doch in der Praxis sind agentische Workflows fast immer erforderlich, um den Anforderungen der Technischen Kommunikation gerecht zu werden.
RAG kann damit nicht als Ersatz, sondern als Baustein verstanden werden. Also als ergänzender Mechanismus innerhalb eines umfassenderen Systems für KI-gestützte Content Delivery.
Quellen:
[1] Schluntz, E. / Zhang, B. (2024): „Building Effective AI Agents“. <https://www.anthropic.com/engineering/building-effective-agents > [Stand: 19.12.2024, Zugriff: 19.06.2025, 15:00 MESZ]





